千变万化
芯算未来
TensorChip与兆易创新GD32 MCU携手推进AI算法的芯片级加速
近日,千芯科技(北京)有限公司(TensorChip)与兆易创新GD32 MCU携手,在人工智能与RISC-V生态领域开展多方位、多层次的人工智能生态合作,共同为客户提供基于TensorChip和兆易创新技术的AI算法芯片级加速方案。
AI正走向“算法-芯片协同设计”的道路
大部分AI芯片企业往往重点关注芯片内部的优化与加速,忽视与AI算法的协同,以及AI算法与芯片架构的匹配。即便拥有较好的芯片算力,在实际AI应用时也仅表现出较弱的有效算力。这导致AI产品成本居高不下,市场竞争力不足。
与单纯的AI算法或芯片公司不同,TensorChip的技术路线更接近于苹果公司与Google等硅谷企业。TensorChip致力于人工智能领域算法-芯片协同设计与加速,通过先进的算法-芯片一体技术打通算法和编译、芯片间的优化壁垒,通过定域可重构技术为人工智能领域提供优质算力支持。目前其产品已经应用于云计算加速、车载平台计算等领域。
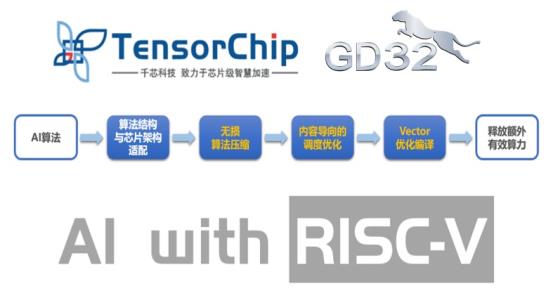
在RISC-V领域,TensorChip提供了先进的芯片级算法加速包——TensorSpeed,可以将客户自有AI算法通过领先的无损AI算法压缩及Vector优化编译技术,释放额外的有效算力,高效运行在RISC-V芯片或IP上,从而降低客户算法落地难度和成本,并缩短产品上市时间。
构筑算法-芯片一体的AI加速平台
兆易创新GD32 MCU是中国高性能通用微控制器领域的领跑者,发布的全球首个基于RISC-V内核的GD32V系列32位通用MCU产品,提供了从芯片到程序代码库、开发套件、设计方案等完整工具链支持并持续打造RISC-V开发生态。GD32V提供易用、高效能、成本效率等优势,全面支持多层次开发并占据先机。相应产品可广泛应用于工业控制、智慧家庭、智慧数码产品、智慧玩具与AIoT领域。
GD32与TensorChip携手构筑算法-芯片的协同AI加速平台,通过先进的算法压缩及算芯协同技术,将释放出RISC-V的额外等效算力,进一步强化GD32V系列MCU产品在AIoT领域的领先优势,并为相应领域客户提供更多更便捷的一体化方案选择。
TensroChip的硬科技
TensorChip的研发核心团队由来自北美AI巨头、瑞萨与国内的芯片及人工智能领域资深专家组成,致力于国际领先的AI算法-芯片协同设计(算芯协同),聚焦AI算法及芯片系统在应用领域的落地。
TensorChip的算芯一体AI加速技术,可以通过对人工智能算法的编译优化处理与硬件平台匹配,并辅以领先的无损算法压缩技术,协助用户在短时间内将算法与芯片平台的结合,形成定制化软硬件一体高效方案。帮助客户实现最佳平台落地,降低客户算法落地门槛和成本,加速产品上市从而形成竞争力。
TensorChip目前正通过定制化合作,协助客户将自有算法在FPGA平台、RISC-V架构、及x86架构产品落地。合作伙伴包括AI芯片企业与AI算法企业。未来,TensorChip会与合作伙伴一起,推出可重构的存算一体芯片方案和对应的算法编译平台,在人工智能批量投产时代提供最具市场竞争力的芯片平台方案。